GB200网络架构的问题从周二一直研究到周五,各种猜想分歧很大,原因也很明显,NV留了一个盲点,要么方案他们内部也没确定好,要么还有新东西等后面发布。今天仔细梳理了过去一周的所有信息,大概有了眉目。
首先,让我们回到GTC之前被广泛流传的那份Taiwan报告(后来线下肉身见到了报告原机构的taiwan兄弟,他们也没想到流传这么广....),鉴于其准确度几乎99%,特意回去看了下报告中对NVL72网络部分的描述:

这就是GTC上发布的NVL72,上面写的清清楚楚,这一款是“Non-scalable”,不可扩展。原因也很简单,18个GPU tray:9个NVLink Switch tray,也就是72 GPU:18 NVS ASIC芯片。72张GPU 1.8TB/s双向互联总带宽需求是72*1.8=129.6TB,18个NVS ASIC也就提供了18*7.2TB=129.6TB(就是这么配的),意味着负责把72张GPU全部互联的所谓下行带宽已经占满了这9个NVS tray的全部端口,根本没有留出上行带宽。那怎么办呢?报告中提供了NV另一种方案――2个36

而且写的清清楚楚,这款是“scalable”的NVS,因为单rack内的GPU:NVS ASIC比例降低了一半,36:18,下行负载和上行负载各占一半。报告中描述如下:
这两个36机柜是“back to back”背对背
每个NVS tray一半端口连接背板,一半端口连接18个OSFP(扩展端口)
rack to rack用的啥?LACC Linear Active Copper Cables(但要特别注意,这里仅仅可以明确是2个36机柜之间用铜;更多rack的互联,OSFP理论上可铜可光,且LACC的距离限制估计比较难满足最远rack之间的连接,大概率还是光)
这就很清楚了。要扩展,就用36卡的机柜。既可以用LACC连接隔壁rack的交换机,扩展为一个72卡的NVL72。也可以继续扩展更多rack,比如大家关心的576卡,一共16个小rack(8个大rack),但这就需要再加一层NVS 网络了(类似GH200),每个rack的L1 NVS端口一半上行连接到L2(前提是无阻塞上行)。但到这里,分歧来了。你会听到有人说类似GH200 1:9,有人说第二层直接走back end网络也就是IB,那就是1:2.5/3.5等等。当然,也出现了另一种最为激进的理论,就是576卡(8 72 rack或 16个36 rack)之间全部或者一半用了full mesh,直接走铜...这个似乎过于激进...因为首先1)在rack距离进一步压缩之前,这可以说是挑战铜的物理极限了...(如果是真的我给NV跪了)。2) blackwell这一代的理念就是尽量向前兼容供应链,你说72内用了这么多铜已经invovle了新供应商,用更多,似乎供应链也不太支持。
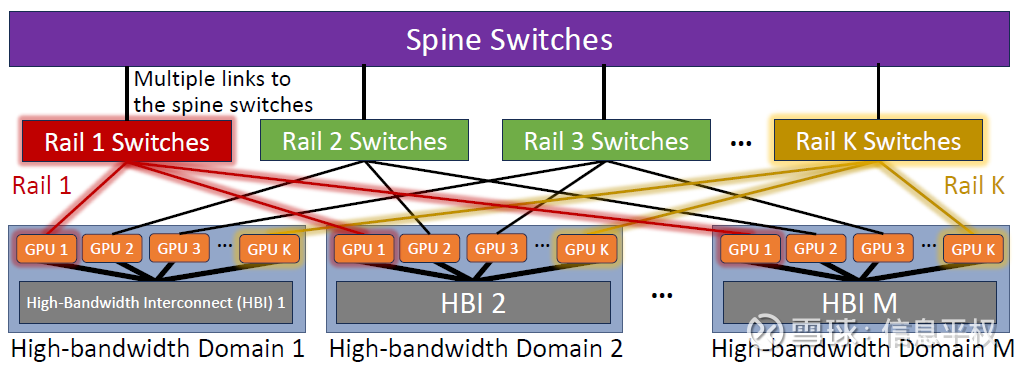
分歧的核心在哪儿呢?首先,NVLink覆盖的是超节点(专业名词叫HB,high-bandwidth Domain),而IB覆盖的是超节点之上的网络扩展。这一代NVLink选址范围domain,也就是HB Domain在36-576之间。每个客户选择将NVLink domain做到多大,或者用NVlink实现全互联的颗粒度多大,产生了本质区别。比如HB颗粒度我选择72,那好,非常省钱,NVL72之上直接走IB,只需要1层铜NVL+IB; 但比如我HB颗粒度打满到576,那好,巨贵,2层NVL+IB(和GH200一样的1:9)。你会问,为什么HB不定144、288。因为这代交换机tray端口144,按照全互联端口充分利用的角度,144*144*2/18(18是GPU NVlink ports)=576。继续拆解上述问题:
1. 成本问题。也是上代GH200的痛点。将NVlink寻址范围做到256,用了2层网络1:9,代价是256个卡对应2304个800G(还没算IB哦),即250万美金光模块,对应单卡成本就增加了1万美金,也就是GPU成本的50%....哪个客户愿意买?因此这代NVL72实现了上代GH200 256卡一样的算力且NVLINK全连接,但打掉了1:9的光模块!直接降低了组网成本。前提是你的HB颗粒度选择定在72。如果你在训练超大模型(10万亿参数)或超大模型推理,那好,有可能这个客户会选择HB domain定在576,那你就要接受5184个1.6T光模块即1244万美金,对应单卡成本增加2万美金,也就是GPU成本的60%....
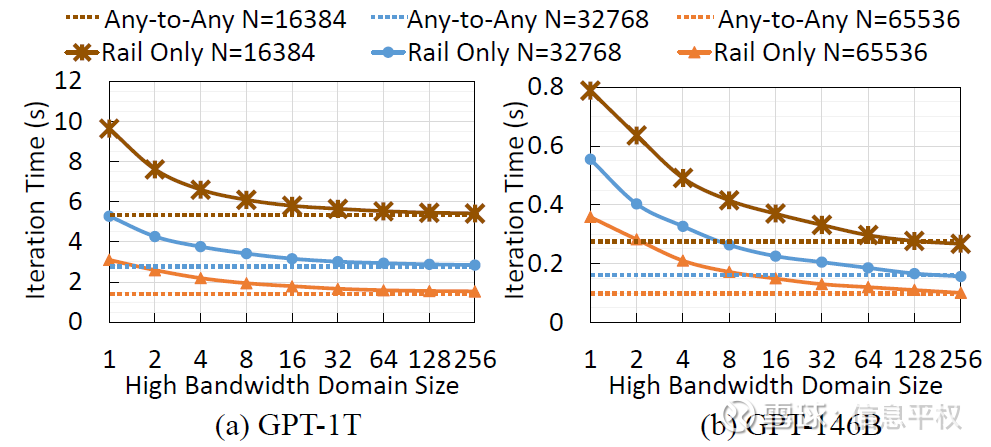
2. 需求问题:小模型训练、微调、推理,当然1EFlops的NVL72就解决了,不在我们讨论范围。我们更关心的是未来的前沿模型超大集群训练和推理,到底HB domain或者NVL domain应该如何选?这个关键问题,恰好一位HW网络大神给了我一份非常重要的paper(已传星球),你说巧不巧...这是Meta和MIT一起搞的研究,结论就是超节点GH200做到256就够了,再往上边际效果快速降低。此外IB网络需要1层其实也就够了。
但这个研究有个问题,其考虑的最大模型就是1万亿参数,显然没考虑未来即将出现的10万亿甚至几十万亿参数模型。虽然不清楚,但似乎可以线性外推,随着模型参数*10,是否意味着最优HB domain也需要*10。那可能意味着的确目前的NVL72做HB对现有模型完全足够,但未来模型真不一定够用...
3. 供给问题。和问题2对上了,还是那份tw报告,从中窥探到NVLink寻址范围会到2000+,继续用之前计算方法,假设下一步NVS tray继续double 成4颗die,端口乘以2,那么2层NVL全互联的最优节点是多少?288*288/2/18=2304。数不一定对,因为下一代端口数、NVLink ports数都可能略微不同。意味着英伟达基于自己对最前沿模型(比如OpenAI)的洞察,HB Domain还会上升....
4. 另一个供给问题。芯片还会继续压缩,下一代X100比如4颗die的chiplet,意味着目前576卡的算力,很有可能下一代也只需要76卡..什么意思?又全给塞到一个机柜里,又可以用一层NVL铜了...(当然这需要交换机ASIC等等要一起翻倍)
因此,这个问题是一个复杂函数,多个反向因子,相互影响。还没考虑越来越快的serdes迭代速度、模型迭代速度、推理复杂度急速提升、硅光/CPO/LPO等其他技术加速.....想到这我脑子已经炸了,下次再继续写,只求老黄在ComputeX上给出更多答案....